『ビジョン2021-2025 国立国会図書館のデジタルシフト』
LINE株式会社AIカンパニーは7月15日、国立国会図書館が保有するデジタル化資料のOCRテキストデータ化プロジェクトに「CLOVA OCR」が採用されたと発表した。
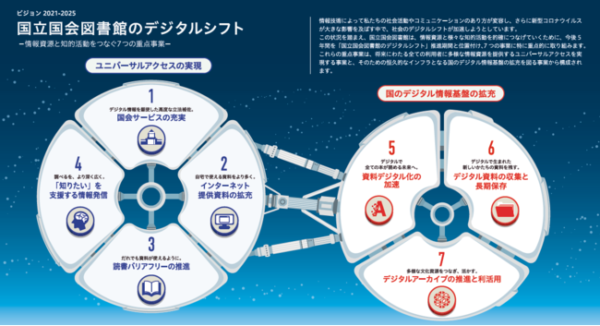
国立国会図書館では「ビジョン2021-2025 国立国会図書館のデジタルシフト」の一環として、来年3月までに247万点のデジタル化資料をテキストデータ化する取り組みが行われている。
OCRとは画像データや印刷物のテキスト部分を認識し、文字データに変換する機能。同プロジェクトは、視覚障がい者や高齢者を含む全ユーザーの利便性向上、アクセスの飛躍的な拡大を目指している。
今回テキストデータ化するデジタル化資料の多くは昭和前期以前の資料であり、レイアウトも複雑なため、学習機能のない既存のOCRでは同プロジェクトに必要な精度に達しないことや、2億2300万枚超の資料解析に時間を要する点が課題となっていた。
同社が開発した「CLOVA OCR」は同プロジェクトで要求される「ルビ」「割注」「割書き」といった特殊な文書に関し、人手を介さずに読み取りするなど、最適なOCRモデルを開発・実現することができる。
